16
Mar
If you’re looking for divisive hierarchical clustering example pictures information linked to the divisive hierarchical clustering example topic, you have come to the right blog. Our site frequently gives you hints for viewing the maximum quality video and image content, please kindly search and find more informative video articles and images that fit your interests.
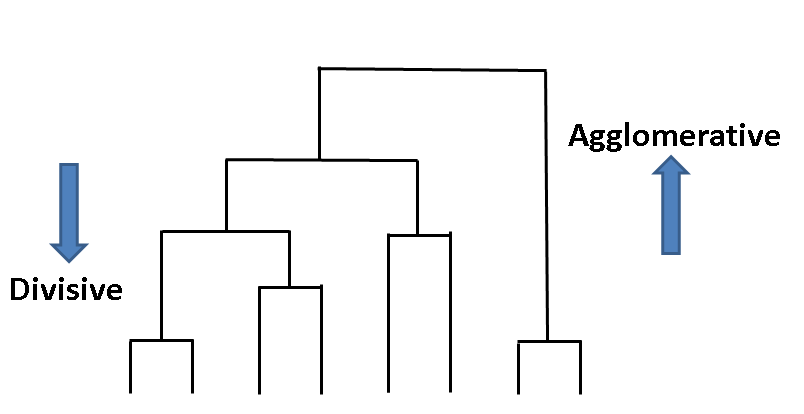
Divisive Hierarchical Clustering Example. The algorithms were tested on the Human Gene DNA Sequence dataset and dendrograms were plotted. This article introduces the divisive clustering algorithms and provides practical examples showing how to compute divise clustering using R. Here we start with a single cluster consisting of all the data points. For example clusters C1 and C2 may be merged if an object in C1 and an object in C2 form the minimum Euclidean distance between any two objects from different clusters.
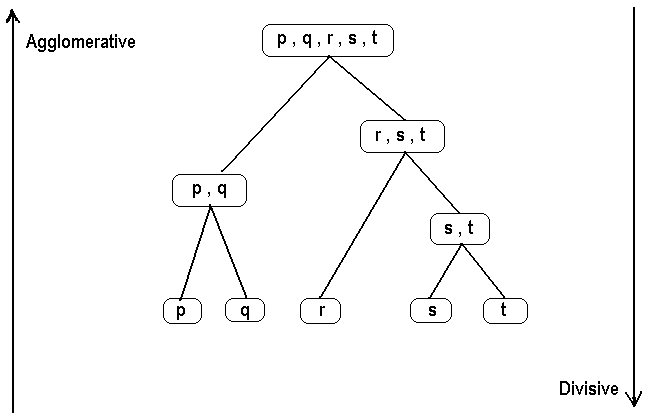
About Press Copyright Contact us Creators Advertise Developers Terms Privacy Policy Safety How YouTube works Test new features Press Copyright Contact us Creators. The divisive hierarchical clustering also known as DIANA DIvisive ANAlysis is the inverse of agglomerative clustering. Partition the cluster into two least similar cluster. The algorithms were tested on the Human Gene DNA Sequence dataset and dendrograms were plotted. Time complexity of a naive agglomerative clustering is On 3 because we exhaustively scan the N x N matrix dist_mat for the lowest distance in each of N-1 iterations. Repeat until all clusters are singletons a choose a cluster to split what criterion.
The divisive hierarchical clustering also known as DIANA DIvisive ANAlysis is the inverse of agglomerative clustering. The cluster is further split until there is one cluster for each data or observation. This is a single-linkage approach in that each cluster is represented by all of the objects in the cluster and the similarity between two clusters is measured by the similarity of the closest pair of data points belonging to. Hierarchical clustering is another unsupervised machine learning algorithm which is used to group the unlabeled datasets into a cluster and also known as hierarchical cluster analysis or HCA. Put all objects in one cluster 2. Initially all points in the dataset belong to one single cluster.
Previous post
Dj shadow in fluxuationsNext post
Distillation purification of water